import pandas as pd
import warnings
warnings.filterwarnings(
"ignore",
category=UserWarning,
module="openpyxl.styles.stylesheet"
)Dataset hentet fra UFM.
df = pd.read_excel("data/day22/Reelt optagne_alder.xlsx")df.head(5)| Den Koordinerede Tilmelding | Unnamed: 1 | Unnamed: 2 | Reelt optagne uanset prioritet fordelt på alder | Unnamed: 4 | Unnamed: 5 | Unnamed: 6 | Unnamed: 7 | Unnamed: 8 | Unnamed: 9 | Unnamed: 10 | Unnamed: 11 | Unnamed: 12 | Unnamed: 13 | Unnamed: 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | 21-juli-2025 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | InstNr | InstNavn | OptNr | OptNavn | Yngre | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | 24.0 | 25.0 | 26-30 | Ældre | I alt |
| 3 | 1000 | Københavns Universitet | 10110 | Medicin, København Ø, Studiestart: sommer- og ... | 26 | 71.0 | 110.0 | 127.0 | 81.0 | 21.0 | 18.0 | 5.0 | 12 | 7 | 478 |
| 4 | 1000 | Københavns Universitet | 10112 | Medicin, Køge, Studiestart: sommer- og vinters... | 6 | 15.0 | 20.0 | 26.0 | 23.0 | 14.0 | 13.0 | 3.0 | 6 | 8 | 134 |
# Fjerne 2 første rækker
df = df.iloc[2:,:]# Tilføje øverste række som kolonne navne
ny_header = df.iloc[0] # Gemme kolonnenavne
df = df.iloc[1:] # Fjerne øverste kolonne fra DataFrame
df.columns = ny_headerdf.head(5)| 2 | InstNr | InstNavn | OptNr | OptNavn | Yngre | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | 24.0 | 25.0 | 26-30 | Ældre | I alt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 1000 | Københavns Universitet | 10110 | Medicin, København Ø, Studiestart: sommer- og ... | 26 | 71.0 | 110.0 | 127.0 | 81.0 | 21.0 | 18.0 | 5.0 | 12 | 7 | 478 |
| 4 | 1000 | Københavns Universitet | 10112 | Medicin, Køge, Studiestart: sommer- og vinters... | 6 | 15.0 | 20.0 | 26.0 | 23.0 | 14.0 | 13.0 | 3.0 | 6 | 8 | 134 |
| 5 | 1000 | Københavns Universitet | 10115 | Folkesundhedsvidenskab, København K, Studiesta... | NaN | 1.0 | 10.0 | 23.0 | 24.0 | 8.0 | 1.0 | NaN | 1 | NaN | 68 |
| 6 | 1000 | Københavns Universitet | 10117 | Farmaci, København Ø, Studiestart: sommerstart | 23 | 42.0 | 49.0 | 51.0 | 33.0 | 18.0 | 4.0 | 2.0 | 4 | 2 | 228 |
| 7 | 1000 | Københavns Universitet | 10120 | Odontologi, København Ø, Studiestart: sommerstart | 13 | 14.0 | 16.0 | 24.0 | 23.0 | 10.0 | 5.0 | 2.0 | 8 | 5 | 120 |
# Pivotere data fra wide til long format for nemmere dataanalyse
melted = pd.melt(df, id_vars=ny_header[:4], value_vars=ny_header[4:-1], var_name='Alder', value_name='Antal')melted.head(5)| InstNr | InstNavn | OptNr | OptNavn | Alder | Antal | |
|---|---|---|---|---|---|---|
| 0 | 1000 | Københavns Universitet | 10110 | Medicin, København Ø, Studiestart: sommer- og ... | Yngre | 26 |
| 1 | 1000 | Københavns Universitet | 10112 | Medicin, Køge, Studiestart: sommer- og vinters... | Yngre | 6 |
| 2 | 1000 | Københavns Universitet | 10115 | Folkesundhedsvidenskab, København K, Studiesta... | Yngre | NaN |
| 3 | 1000 | Københavns Universitet | 10117 | Farmaci, København Ø, Studiestart: sommerstart | Yngre | 23 |
| 4 | 1000 | Københavns Universitet | 10120 | Odontologi, København Ø, Studiestart: sommerstart | Yngre | 13 |
pd.set_option('future.no_silent_downcasting', True)
melted = melted.fillna(0).infer_objects(copy=False)melted.dtypesInstNr int64
InstNavn object
OptNr int64
OptNavn object
Alder object
Antal float64
dtype: objectmelted['Alder'] = melted['Alder'].astype(str)import matplotlib.pyplot as plt
import numpy as npplt.bar(melted['Alder'], melted['Antal'])
plt.xlabel("Alder")
plt.ylabel("Antal")
plt.title("Antal pr. Alder")
plt.xticks(rotation=45)
plt.show()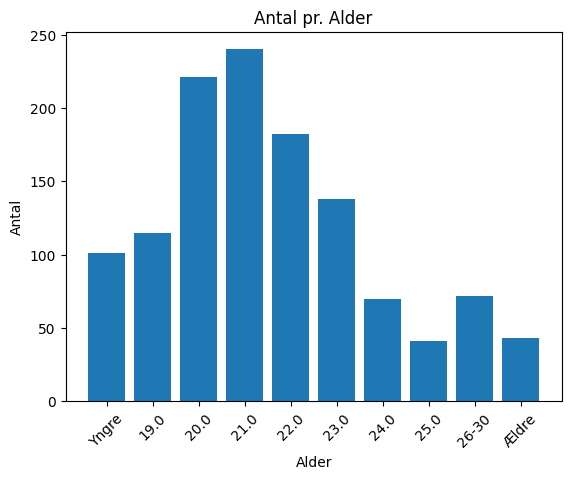
melted['InstNavn'].unique()array(['Københavns Universitet',
'Copenhagen Business School - Handelshøjskolen',
'IT-Universitetet i København', 'Danmarks Tekniske Universitet',
'Roskilde Universitet', 'Syddansk Universitet',
'Aarhus Universitet', 'Aalborg Universitet',
'Det Kongelige Akademi - Arkitektur, Design, Konservering',
'Arkitektskolen Aarhus', 'Designskolen Kolding',
'Københavns Professionshøjskole', 'Professionshøjskolen Absalon',
'Professionshøjskolen UC Syddanmark',
'UCL Erhvervsakademi og Professionshøjskole',
'Professionshøjskolen VIA University College',
'Professionshøjskolen University College Nordjylland',
'Danmarks Medie- og Journalisthøjskole', 'Den Frie Lærerskole',
'Teknika – Copenhagen College of Technology Management and Marine Engineering',
'Svendborg International Maritime Academy, SIMAC',
'Fredericia Maskinmesterskole', 'Aarhus Maskinmesterskole',
'MARTEC - Maritime and Polytechnic University College',
'Erhvervsakademiet Copenhagen Business Academy',
'Københavns Erhvervsakademi (KEA)',
'Zealand Sjællands Erhvervsakademi', 'IBA Erhvervsakademi Kolding',
'Erhvervsakademi SydVest', 'Erhvervsakademi MidtVest',
'Erhvervsakademi Aarhus', 'Erhvervsakademi Dania'], dtype=object)kp = melted[melted['InstNavn'] == 'Københavns Professionshøjskole']# Gruppere kp DataFrame for alder for at kunne summere antal studerende korrekt
kp = kp.groupby('Alder', as_index=False)['Antal'].sum()# Plot af alder for optagne på KPs uddannelser
plt.bar(kp['Alder'], kp['Antal'])
plt.xlabel("Alder")
plt.ylabel("Antal")
plt.title("KP - alder optagne")
plt.xticks(rotation=45)
plt.show()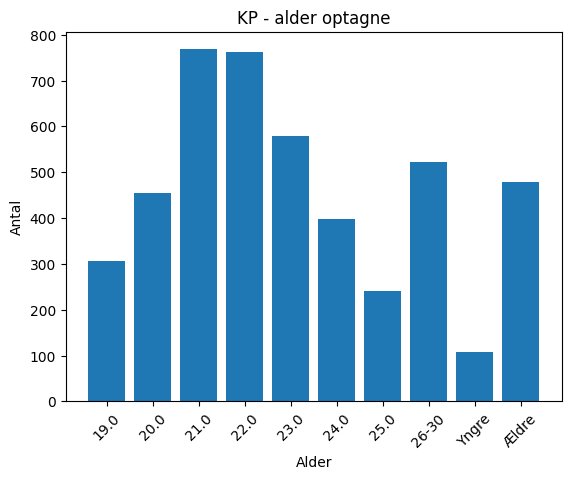
Ekstrapolere distribution
from scipy.stats import skewnorm# Filtere ikke grupperede kategorier i alder fra
kp_filtered = kp.loc[(kp['Alder'] != 'Yngre') & (kp['Alder'] != 'Ældre') & (kp['Alder'] != '26-30')]aldre = kp_filtered['Alder'].unique()aldre.shape(7,)aldre_kp = np.array(aldre)# Sikre at dise arrays har rigtig størrelse
aldre_kp.shape(7,)aldre = aldre.astype('float').astype('int')antal = np.array(kp_filtered.groupby('Alder')['Antal'].sum())antal = antal.astype('float').astype('int')antalarray([307, 454, 768, 762, 580, 398, 241])# Fit af distribution
a, loc, scale = skewnorm.fit(np.repeat(aldre, antal))# Bestemme ny data range
yderligere_aldre = np.arange(18, 30)pdf_værdier = skewnorm.pdf(yderligere_aldre, a, loc, scale)pdf_skaleret = pdf_værdier * antal.sum() / pdf_værdier.sum()# Plot af ekstrapoleret distribution
plt.bar(aldre, antal, label='Kendt data')
plt.plot(yderligere_aldre, pdf_skaleret, label='Ekstrapoleret distribution', color='red')
plt.xlabel('Alder')
plt.ylabel('Antal')
plt.title('Alders distribution - KP')
plt.legend()
plt.show()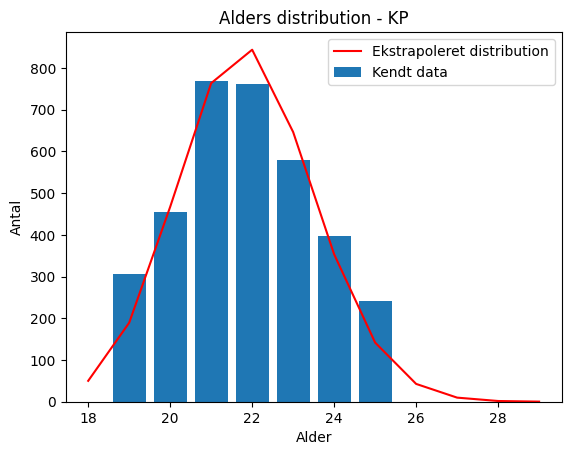
Dette ser ikke helt så godt ud som man havde håbet, da antal studerende falder drastisk fra 26 modsat hvad der sker i datasættet. Dette skyldes at der ikke er taget højde for antal optagne som er yngre end 19 og ældre end 25.
Udregning af chance for at være under 19 år eller over 25 år gammel
yngre_antal = kp.loc[kp['Alder'] == 'Yngre', 'Antal'].sum()yngre_antalnp.float64(107.0)ældre_antal = kp.loc[(kp['Alder'] == '26-30') | (kp['Alder'] == 'Ældre'), 'Antal'].sum()ældre_antalnp.float64(1002.0)p_yngre = yngre_antal / kp['Antal'].sum()p_yngrenp.float64(0.023165187269971854)p_over25 = ældre_antal / kp['Antal'].sum()p_over25np.float64(0.2169300714440355)Altså er der næsten 10 gange større chance for at en person er over 25 end vedkommende er under 19